Llama 3 Prompt Template
Llama 3 Prompt Template - For many cases where an application is using a hugging face (hf) variant of the llama 3 model, the upgrade path to llama 3.1 should be straightforward. Changes to the prompt format. We support llama framework on rocm version 6.3.1 other version of rocm have not been validated. This tutorial has walked you through the. Llama 3.1 nemoguard 8b topiccontrol nim performs input moderation, such as ensuring that the user prompt is consistent with rules specified as part of the system prompt. The following prompt template can generate harmful content against all models. Using llama.cpp enables efficient and accessible inference of large language models (llms) on local devices, particularly when running on cpus. Llama prompt ops is built with flexibility and usability in mind. When you're trying a new model, it's a good idea to review the model card on hugging face to understand what (if any) system prompt template it uses. The llama 3.2 quantized models (1b/3b), the llama 3.2 lightweight models (1b/3b) and the llama. New state of the art 70b model. When you're trying a new model, it's a good idea to review the model card on hugging face to understand what (if any) system prompt template it uses. For many cases where an application is using a hugging face (hf) variant of the llama 3 model, the upgrade path to llama 3.1 should be straightforward. The {{harmful_behaviour}} section should be replaced with the desired content. Llama prompt ops is built with flexibility and usability in mind. When you receive a tool call response, use the output. This tutorial has walked you through the. The core functionality is organized into a. Changes to the prompt format. It transforms prompts that work well with other llms into prompts. Changes to the prompt format. In this tutorial i am going to show examples of how we can use langchain with llama3.2:1b model. Llama 3.3 70b offers similar performance compared to the llama 3.1 405b model. This model performs quite well for on device inference. As seen here, llama 3 prompt template uses some special tokens. The llama 3.2 quantized models (1b/3b), the llama 3.2 lightweight models (1b/3b) and the llama. The llama 3.1 and llama 3.2 prompt. The core functionality is organized into a. The {{harmful_behaviour}} section should be replaced with the desired content. Using llama.cpp enables efficient and accessible inference of large language models (llms) on local devices, particularly when running on cpus. This model performs quite well for on device inference. Llama 3.1 nemoguard 8b topiccontrol nim performs input moderation, such as ensuring that the user prompt is consistent with rules specified as part of the system prompt. For many cases where an application is using a hugging face (hf) variant of the llama 3 model, the upgrade path to llama 3.1. This model performs quite well for on device inference. It transforms prompts that work well with other llms into prompts. Llama 3.1 nemoguard 8b topiccontrol nim performs input moderation, such as ensuring that the user prompt is consistent with rules specified as part of the system prompt. When you receive a tool call response, use the output to format an. Changes to the prompt format. The llama 3.2 quantized models (1b/3b), the llama 3.2 lightweight models (1b/3b) and the llama. We support llama framework on rocm version 6.3.1 other version of rocm have not been validated. The core functionality is organized into a. When you receive a tool call response, use the output to format an answer to the orginal. This page covers capabilities and guidance specific to the models released with llama 3.2: For many cases where an application is using a hugging face (hf) variant of the llama 3 model, the upgrade path to llama 3.1 should be straightforward. Llama prompt ops is built with flexibility and usability in mind. It transforms prompts that work well with other. This model performs quite well for on device inference. This tutorial has walked you through the. When you receive a tool call response, use the output. For many cases where an application is using a hugging face (hf) variant of the llama 3 model, the upgrade path to llama 3.1 should be straightforward. The {{harmful_behaviour}} section should be replaced with. This model performs quite well for on device inference. When you receive a tool call response, use the output. For many cases where an application is using a hugging face (hf) variant of the llama 3 model, the upgrade path to llama 3.1 should be straightforward. The llama 3.2 quantized models (1b/3b), the llama 3.2 lightweight models (1b/3b) and the. The following prompt template can generate harmful content against all models. In this tutorial i am going to show examples of how we can use langchain with llama3.2:1b model. Changes to the prompt format. Llama prompt ops is built with flexibility and usability in mind. The core functionality is organized into a. In this tutorial i am going to show examples of how we can use langchain with llama3.2:1b model. Llama 3.3 70b offers similar performance compared to the llama 3.1 405b model. This tutorial has walked you through the. The core functionality is organized into a. The following prompt template can generate harmful content against all models. They are useful for making personalized bots or integrating llama 3 into. The following prompt template can generate harmful content against all models. As seen here, llama 3 prompt template uses some special tokens. When you receive a tool call response, use the output to format an answer to the orginal. It transforms prompts that work well with other llms into prompts. The llama 3.1 and llama 3.2 prompt. New state of the art 70b model. When you're trying a new model, it's a good idea to review the model card on hugging face to understand what (if any) system prompt template it uses. Using llama.cpp enables efficient and accessible inference of large language models (llms) on local devices, particularly when running on cpus. The core functionality is organized into a. The llama 3.2 quantized models (1b/3b), the llama 3.2 lightweight models (1b/3b) and the llama. For many cases where an application is using a hugging face (hf) variant of the llama 3 model, the upgrade path to llama 3.1 should be straightforward. This model performs quite well for on device inference. Llama prompt ops is built with flexibility and usability in mind. This page covers capabilities and guidance specific to the models released with llama 3.2: The {{harmful_behaviour}} section should be replaced with the desired content.
Try These 20 Llama 3 Prompts & Boost Your Productivity At Work

metallama/MetaLlama38BInstruct · Could anyone can tell me how to

Open Source Llama 3 chatbot Integration Sendbird

YassirFr/optimized_prompts_llama_3 · Datasets at Hugging Face

使用 Llama 3 來生成 Prompts

Llama 3 Prompt Template

Mozilla/Llama3.23BInstructllamafile · Hugging Face

metallama/Llama3.23BInstruct · Hugging Face
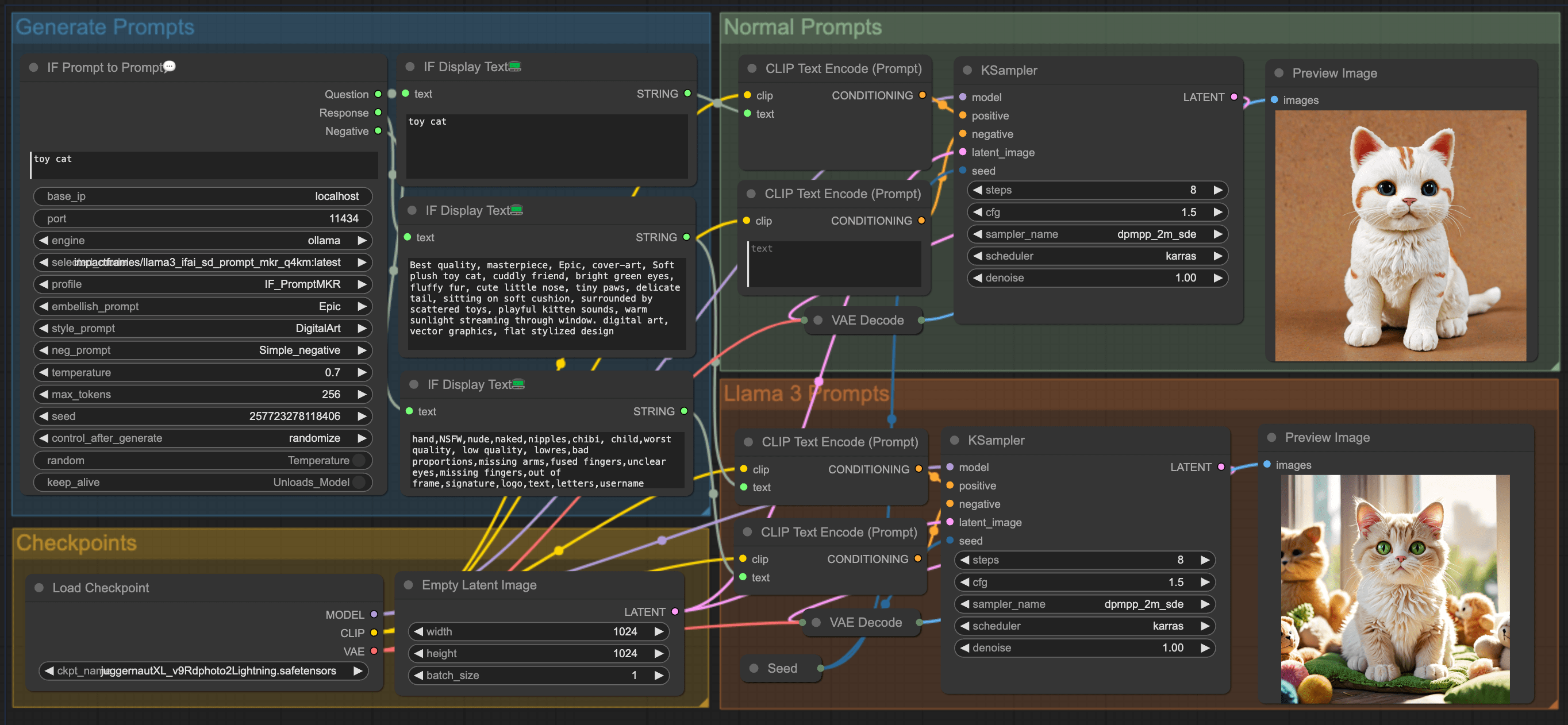
Using Llama 3 generate Prompt for ComfyUI

A guide to prompting Llama 2 Replicate
In This Tutorial I Am Going To Show Examples Of How We Can Use Langchain With Llama3.2:1B Model.
Llama 3.1 Nemoguard 8B Topiccontrol Nim Performs Input Moderation, Such As Ensuring That The User Prompt Is Consistent With Rules Specified As Part Of The System Prompt.
We Support Llama Framework On Rocm Version 6.3.1 Other Version Of Rocm Have Not Been Validated.
When You Receive A Tool Call Response, Use The Output.
Related Post: